
|
Regardless of how well we construct our hashCode() method, we almost always have the possibility that a collision can still occur. Fortunately, there are multiple mechanisms for resolving these collisions:
One way to deal with collisions is change the underlying array from one that stores key-value pairs to one that stores references to linked lists of key-value pairs. This technique of collision resolution in a hash table is known as separate chaining.
When using separate chaining, the insertion of a new key-value pair can be accomplished by simply adding it to the front of the list in the slot corresponding to the hash code, which can be done in constant time.
As a concrete example, suppose the letters of "SEPARATE CHAINING" are used as keys for values 0 to 15, paired respectively. Entering these, as ordered, into a hash table with only 5 slots using separate chaining as its means for collision resolution, results in a hash table filled as shown below.
For convenience, the hash codes (mod 5) for the keys inserted are shown on the left and the value paired with each key indicates when it was inserted relative to the other pairs.

When retrieving the value for a given key, one potentially needs to check all of the elements in the list located at the slot identified by the hash, before concluding that key-value pair is not in the hash table. Granted, this means we will be doing a sequential search through the associated list, which is not terribly efficient. However, if we have done a good job at creating our hash function and used a large enough array in the first place, the lengths of these lists should not be long.
Deletion of a key-value pair from the hash table is similarly done by simply deleting it from the corresponding list.
As a design suggestion, making each list in the array function as a "miniature symbol table" with its own get(), put(), delete() and other methods, will be particularly convenient in keeping the implementation of the hash table simple -- as suggested by the put(), get(), and delete() methods shown below.
public void put(Key key, Value val) {
int h = hash(key);
table[h].put(key, val);
}
public Value get(Key key) {
return table[hash(key)].get(key);
}
public void delete(Key key) {
int h = hash(key);
table[h].delete(key);
}
Notably, the above does not address updating any instance variables storing the number of keys currently in the hash table. The put() and delete() methods would require some additional lines if keeping track of this useful information is also desired.
Another way to react to a collision -- an "already-full" cell at the hash slot for some new key-value pair to be inserted -- is to simply move forward in the array one cell at a time until an empty cell presents itself, and then use that empty cell to store the new key-value pair.
Note that unlike the separate chaining method where key/value pairs are stored in linked lists outside of the array -- this technique, called linear probing, stores all of the key/value pairs directly inside the array. As a matter of vocabulary, when the key/value pairs are stored in the array itself, one is said to be using open addressing.
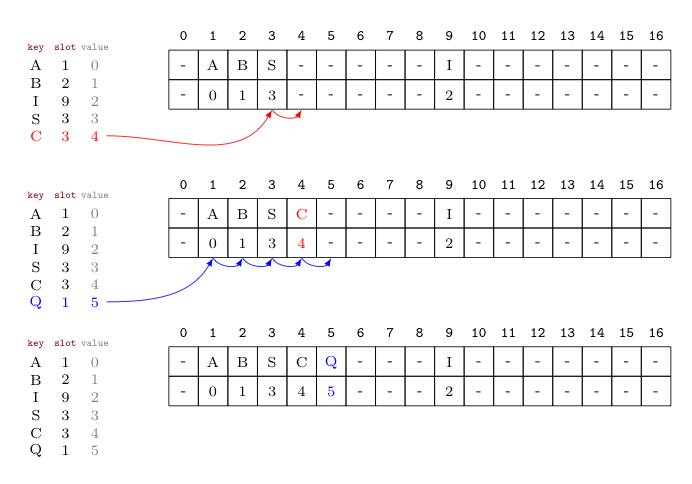
Consider the example shown below. In it, we have a hash table with 16 slots using linear probing. It contains two parallel arrays -- one for the keys stored, another for the paired values.
Suppose the letters of the word "$ABISQ$" are used as keys for values $0$ through $5$, paired respectively. Inserting these, as ordered, into our hash table causes no problems for the first four key-value pairs [i.e, $(A,0)$, $(B,1)$, $(I,2)$, and $(S,3)$].
However, attempting to then add the key-value pair $(C,4)$ causes a collision with key $S$, already in slot $3$. As can be seen below, we find an empty slot immediately to the right of the slot originally intended for $C$, so we put $C$ and its paired value there instead (shown in red below).
Attempting to then insert the key-value pair $(Q,5)$ we see another collision -- this time with the key $A$ in slot $1$. We find the first empty slot to its right four slots away, and thus insert $Q$ and its value there (shown in blue below).
If while searching for an empty slot, we should reach the end of the array without finding one, we simply wrap back to the beginning and keep looking from there. This is easily accomplished with a simple for-loop and the mod operator, %, in the heart of the put() method -- as shown below.
int i;
for (i = hash(key); keys[i] != null; i = (i+1) % M) {
if (keys[i].equals(key)) {
vals[i] = val;
return;
}
}
keys[i] = key;
vals[i] = val;
Retrieval of the value associated with a given key via the get() is done in a similar manner. Only this time, if we reach an empty slot, we assume the desired key is not present and return null. Here's the relevant code:
for (int i = hash(key); keys[i] != null; i = (i+1) % M) {
if (keys[i].equals(key))
return vals[i];
}
return null;
Unlike separate chaining, which degrades gracefully when the client puts more key-value pairs into the hash table then it has slots (i.e., the "chains" just get long and take $O(n)$ to search), when the client does the same in a hash table using linear probing the results can be catastrophic if we don't ensure there are always empty slots in the array (i.e., the code above will result in an infinite loop when the array fills completely).
As such, we will require array resizing, as needed, during its insertion process. Indeed, to ensure good performance one should use resizing to keep the percentage of table slots that are full (called the load factor) between $1/8$ and $1/2$.
Notably, doubling the number of slots in the array during a resize affects all of the previous calculations of insertion positions done using the mod operator.
As such, rather than just copying the key-value pairs from the old array to a new one, we create an entirely new and twice-as-big hash table (whose hash function now depends on its new size) and re-insert all of the keys of the old table into it. This forces a recalculation of all slots used, including any different collision resolutions that results.
With the above strategy in mind, here's a possible implementation of the resize() method:
private void resize(int capacity) {
LinearProbingHashTable t;
t = new LinearProbingHashTable(capacity);
for (int i = 0; i < M; i++) {
if (keys[i] != null)
t.put(keys[i],vals[i]);
}
this.keys = t.keys;
this.vals = t.vals;
this.M = t.M;
}
Of course, the creation of a new hash table twice the size of the original one requires a constructor for our hash table class to which we can pass some sort of capacity argument -- so we'll need to add that too.
Just like with stacks, when resizing happens there is a performance hit -- but this can be amortized over the many more insertions and deletions that occur without any resizing.
Should one not wish a gradual degradation of performance in a hash table employing separate chaining as more and more key-value pairs are inserted, a similar strategy of resizing arrays can be employed in those hash tables as well -- resizing when the average length of the lists involved (i.e., # keys inserted / # slots) drops below $2$ or exceeds $8$.
As for the deletion of elements from a hash table using linear probing, consider what would happen if we deleted the key-value pair corresponding to $S$ above and then tried to update the value paired with $Q$.
The removal of $S$ would create an empty slot 3. Then, calling upon put() to update $Q$'s value, this method would erroneously conclude that $Q$ represented a new key-value pair since -- starting at slot $1$ and moving to the right -- it finds an empty slot before finding $Q$.
The fix for this problem is to reinsert into the table all of the keys in the cluster to the right of the deleted key, as shown in the code below.
public void delete(Key key) {
if (! contains(key)) return;
int i = hash(key); // find where key is in array
while (!key.equals(keys[i]))
i = (i+1) % M;
keys[i] = null; // remove the key value pair there
vals[i] = null;
i = (i+1) % M;
while (keys[i] != null) { // reinsert keys possibly affected by deletion
Key keyToRedo = keys[i]; // think carefully about how this reinsertion
Value valToRedo = vals[i]; // process is performed
keys[i] = null;
vals[i] = null;
size--;
put(keyToRedo, valToRedo);
i = (i+1) % M;
}
size--; // decrement count of items in hash table
if (size > 0 && size == M/8) // resize down, if necessary, so we don't waste space
resize(M/2);
}
One of the problems with linear probing is that after a number of insertions, there can be a build-up of large groups of consecutive filled cells in the array. This is called clustering and can create delays in further insertions as it takes time after a collision in such a cluster to get past these elements and find a free slot.
Another open addressing technique for resolving collisions, known as quadratic probing, attempts to avoid this difficulty by moving forward in the array upon a collision not by a single cell at a time, but rather by ever increasing spans of cells (wrapping back to the front of the array, as necessary).
As an example, consider an associated array with $m=2^p$ cells and some key $k$ that hashes to index h(k) % m. Upon a collision, one probes one cell to the right to see if that cell is open. If it is not open, then one looks 2 cells to the right of that position; then 3 cells to the right; and then 4 cells, etc., upon seeing additional collisions, until a free slot is found.
Recalling the sum of the arithmetic sequence $\displaystyle{1+2+3+\cdots+i}$, one can see that in attempting to insert (or find) a key $k$ the position probed after the $i^{th}$ collision has index given by
$$p(k,i) = \left[ h(k) + \frac{i^2}{2} + \frac{i}{2}\right]\pmod{m}$$Note that this position is determined by adding to $h(k)\pmod{m}$ a function that is quadratic in terms of the number of collisions. This is the defining characteristic that gives quadratic probing its name!
In general, methods of quadratic probing will always have a probe sequence of the form $$p(k,i) = [ h(k) + c_2 i^2 + c_1 i ]\pmod{m}, \quad \textrm{ where } c_2 \ne 0$$ However, care must be taken when picking $c_1$ and $c_2$. For many such pairs, there is no guaranteed of finding an empty cell once the table becomes more than half full, or even before this if the array size is composite. Indeed, for many array sizes, the probe function will simply cycle through a relatively small number of slots. Consequently, if all slots on that cycle happen to be full, then the key/value pair can't be inserted at all -- even if other slots in the table are empty.
Fortunately, the probe sequence in our earlier example (where $c_1 = c_2 = 1/2$) does not suffer from this problem. As long as the array size is a power of $2$, then every cell in the array will eventually be probed, regardless of the key.
Quadratic probing eliminates the type of clustering seen in linear probing (called primary clustering), but is still associated with a milder form of clustering (called secondary clustering). Consider the case where two keys hash to the same initial probe position. Given the nature of the probing function, such keys will follow identical probe sequences and thus will have an increased risk of collisions. This is due to the fact that the "jumps to the right" that occur as subsequent collisions are encountered, are determined solely by the number of collisions encountered and not the key involved.
We can address this problem with yet another open addressing technique called double hashing which uses a second auxiliary hash function $h'$ to create a probing function of the following form
$$p(k,i) = \left[ h(k) + i \cdot h'(k) \right]\pmod{m}$$Importantly, the value of $h'(k)$ must be relatively prime to the array size $m$ for the entire array to be searched. To see why this is important, consider the following example where $h'(k)$ is not relatively prime to $m$: Suppose $m=15$, $h(k)=7$ and $h'(k)=10$, noting that $m$ and $h'(k)$ share a common factor of $5$ and are thus not relatively prime. The sequence of positions probed for the associated key $k$ is then given by $7, 2, 12, 7, 2, 12, \ldots$, which clearly fails to eventually probe all of the cells of the array. Similar problems happen whenever $h'(k)$ and $m$ share a factor other than 1.
A convenient way to ensure $h'(k)$ and $m$ are relatively prime is to let $m$ be a power of $2$ and design $h'$ to always produce an odd number.
While clustering is greatly reduced with this technique, note that it does come at the cost of more computation with the addition of the auxiliary hash function.