|
A frequency distribution is often used to group quantitative data. Data values are grouped into classes of equal widths. The smallest and largest observations in each class are called class limits, while class boundaries are individual values chosen to separate classes (often being the midpoints between upper and lower class limits of adjacent classes).
For example, the table below gives a frequency distribution for the following data:
$$\textrm{Data values: } 11, 13, 15, 15, 18, 20, 21, 22, 24, 24, 25, 25, 25, 26, 28, 29, 29, 34$$ $$\begin{array}{c|c|c} \textrm{Class Limits} & \textrm{Class Boundaries} & \textrm{Frequency}\\\hline 10 - 14 & 9.5 - 14.5 & 2\\\hline 15 - 19 & 14.5 - 19.5 & 3\\\hline 20 - 24 & 19.5 - 24.5 & 5\\\hline 25 - 29 & 24.5 - 29.5 & 7\\\hline 30 - 34 & 29.5 - 34.5 & 1\\\hline \end{array}$$ Frequency distributions should typically have between 5 and 20 classes, all of equal width; be mutually exclusive; continuous; and exhaustive.One should use nice "round" numbers for your class limits as long as there is not a compelling reason to avoid doing so. It will make your frequency distribution easier to read. For example, if your data starts with 43, 46, 48, 48, 52, 57, 58, ... you might pick a lower class limit of 40 and a class width of 5 (provided that a reasonable number of classes resulted)
A relative frequency distribution is very similar, except instead of reporting how many data values fall in a class, they report the fraction of data values that fall in a class. These are called relative frequencies and can be given as fractions, decimals, or percents.
A cumulative frequency distribution is another variant of a frequency distribution. Here, instead of reporting how many data values fall in some class, they report how many data values are contained in either that class or any class to its left.
The below table compares the values seen in a frequency distribution, a relative frequency distribution, and a cumulative frequency distribution, for the following sequence of dice rolls $$\textrm{Dice Rolls: } 7, 6, 7, 6, 7, 4, 4, 6, 10, 5, 6, 11, 4, 8, 2, 9, 6, 5, 3, 8, 3, 3, 12, 9, 10, 7, 6, 7, 4, 6$$ $$\begin{array}{c|c|c} \textrm{Class Limits} & \textrm{Class Boundaries} & \textrm{Frequency} & \textrm{Relative Frequency} & \textrm{Cumulative Frequency}\\\hline 2 - 3 & 1.5 - 3.5 & 4 & 2/15 & 4\\\hline 4 - 5 & 3.5 - 5.5 & 6 & 1/5 & 10 \\\hline 6 - 7 & 5.5 - 7.5 & 12 & 2/5 & 22\\\hline 8 - 9 & 7.5 - 9.5 & 4 & 2/15 & 26\\\hline 10 - 11 & 9.5 - 11.5 & 3 & 1/10 & 29\\\hline 12 - 13 & 11.5 - 13.5 & 1 & 1/30 & 30 \end{array}$$
A frequency histogram is a graphical version of a frequency distribution where the width and position of rectangles are used to indicate the various classes, with the heights of those rectangles indicating the frequency with which data fell into the associated class, as the example below suggests.
Frequency histograms should be labeled with either class boundaries (as shown below) or with class midpoints (in the middle of each rectangle).

One can, of course, similarly construct relative frequency and cumulative frequency histograms.
The purpose of these graphs is to "see" the distribution of the data. When using a calculator or software to plot histograms, experiment with different choices for boundaries, subject to the above restrictions, to find out which graphical properties (modality, skewness or symmetry, outliers, etc...) persist and which are just spurious effects of a particular choice of boundaries. Then use the boundaries that best reveal these persistent properties.
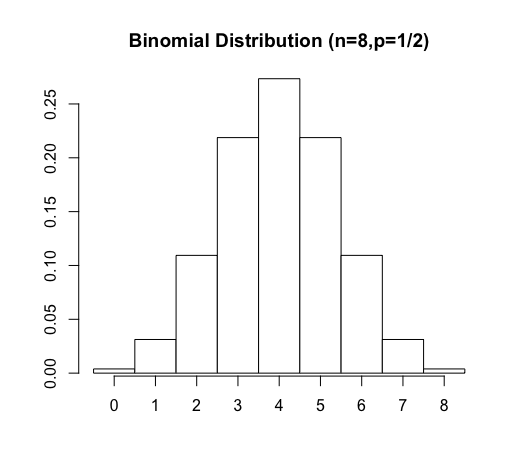
A type of graph closely related to a frequency histogram is a probability histogram, which shows the probabilities associated with a probability distribution in a similar way.
Here, we have a rectangle for each value a random variable can assume, where the height of the rectangle indicates the probability of getting that associated value.
When the possible values the random variable can assume are consecutive integers, the left and right sides of the rectangles are taken to be the midpoints between these integers -- which forces them to all end in $0.5$. Additionally, the width of each rectangle is then $1$, which means that not only the height of the rectangle equals the probability of the corresponding value occurring, but the area of the rectangle does as well. (These observations become very important later when we apply a "continuity correction" to approximate a discrete probability distribution with a continuous one.)