
|
The following code creates in R the $5 \times 5$ matrix shown below.
$$\begin{bmatrix} 11 & 12 & 13 & 14 & 15\\ 21 & 22 & 23 & 24 & 25\\ 31 & 32 & 33 & 34 & 35\\ 41 & 42 & 43 & 44 & 45\\ 51 & 52 & 53 & 54 & 55 \end{bmatrix}$$
> m = rbind(c(11,12,13,14,15),
c(21,22,23,24,25),
c(31,32,33,34,35),
c(41,42,43,44,45),
c(51,52,53,54,55))
Using the above, write R code to generate the following sub-matrices of m:
the sub-matrix of elements in rows 3, 4, or 5 and in columns 1 or 2
the sub-matrix formed by deleting columns 2 and 4
the sub-matrix of rows whose first column element has an even ten's digit
the sub-matrix of elements in column 5 that correspond to an element in the same row and the first column that is less than 50. (Hint: the result should be a column matrix, not a vector.)
# (a)
> m[3:5,1:2]
[,1] [,2]
[1,] 31 32
[2,] 41 42
[3,] 51 52
# (b)
> m[,-c(2,4)]
[,1] [,2] [,3]
[1,] 11 13 15
[2,] 21 23 25
[3,] 31 33 35
[4,] 41 43 45
[5,] 51 53 55
# (c)
> m[(m[,1] %/% 10) %% 2 == 0,]
[,1] [,2] [,3] [,4] [,5]
[1,] 21 22 23 24 25
[2,] 41 42 43 44 45
# (d)
> m[m[,1]<50,5,drop=FALSE]
[,1]
[1,] 15
[2,] 25
[3,] 35
[4,] 45
Use R to determine the matrix product (in the traditional mathematical sense) of the following matrices:
$$A = \begin{bmatrix} 7 & 8 & 2 \\ 5 & 9 & 1 \\ 4 & 6 & 3 \end{bmatrix} \quad \textrm{ and } \quad B = \begin{bmatrix} 13 & -17\\ 0 & 19\\ -3 & -5 \end{bmatrix}$$There are many ways to construct the matrices in question before multiplying them together. Below, we use the matrix() function to create matrix $A$ and the cbind() function to create matrix $B$. Note that byrow=FALSE in the matrix() function by default, so we don't have to specify it when we list the matrix contents by column. Also remember there is a rbind() function we could have used too.
> A = matrix(c(7,5,4,8,9,6,2,1,3),nrow=3)
> B = cbind(c(13,0,-3),c(-17,1,-5))
> A %*% B
[,1] [,2]
[1,] 85 -121
[2,] 62 -81
[3,] 43 -77
Matrices can be used to solve systems of linear equations. For example, one can solve for $x$, $y$, and $z$ in the system of equations $$\begin{align*} ax + by + cz &= p\\ dx + ey + fz &= q\\ gx + hy + iz &= r\\ \end{align*} $$ by finding the product $$\begin{bmatrix}x\\y\\z\end{bmatrix} = \begin{bmatrix} a & b & c\\ d & e & f\\ g & h & i \end{bmatrix}^{-1} \cdot \begin{bmatrix}p\\q\\r\end{bmatrix}$$ Use a similar calculation to solve the following system:
$$\begin{align*} 2x-y+5z+w &= -3\\ 3x+2y+2z-6 &= -32\\ x+3y+3z-w &= -47\\ 5x-2y-3z+3w &= 49 \end{align*}$$
> M = rbind(c(2,-1,5,1),
c(3,2,2,-6),
c(1,3,3,-1),
c(5,-2,-3,3))
> C = rbind(-3,-32,-47,49)
> solve(M) %*% C
[,1]
[1,] 2
[2,] -12
[3,] -4
[4,] 1
Alternatively, one can simply execute the following and get the same answer:
> solve(M,C)
So $x=2, y=-12, z=-4, \textrm{ and } w=1$.
Suppose the following matrix is defined in R: $$\bf{A} = \begin{bmatrix}1 & 1 & 3\\5 & 2 & 6\\-2 & -1 & -3\end{bmatrix}$$
Use R to verify that $\bf{A}^3 = \bf{0}$ where $\bf{0}$ is a $3 \times 3$ matrix with every entry equal to $0$.
Use R to create a new matrix $\bf{B}$ equal to $\bf{A}$, except that its third column has been replaced by the sum of its second and third columns.
Check (a) with
A %*% A %*% A
For (b), the matrix B should display as the following:
> B
[,1] [,2] [,3]
[1,] 1 1 4
[2,] 5 2 8
[3,] -2 -1 -4
Create a $6 \times 10$ matrix of random integers chosen from $1,2,\ldots,10$ by executing the following two lines of code:
set.seed(75) m = matrix( sample(10, size=60, replace=T), nrows=6)
Use R to find the number of entries in this matrix which are greater than 4.
sum(m>4)
Create the following patterned matrices. In each case your solution should make use of the special form of the matrix -- this means that the solution should easily generalize to creating a larger matrix with the same structure and should not involve typing in all the entries of the matrix.
(a) $\displaystyle{ \begin{bmatrix} 0 & 1 & 2 & 3 & 4\\ 1 & 2 & 3 & 4 & 0\\ 2 & 3 & 4 & 0 & 1\\ 3 & 4 & 0 & 1 & 2\\ 4 & 0 & 1 & 2 & 3 \end{bmatrix}}$ (b) $\displaystyle{ \begin{bmatrix} 0 & 1 & 2 & 3 & 4 & 5 & 6 & 7 & 8 & 9\\ 1 & 2 & 3 & 4 & 5 & 6 & 7 & 8 & 9 & 0\\ \vdots & \vdots &\vdots &\vdots &\vdots &\vdots &\vdots &\vdots &\vdots &\vdots &\\ 8 & 9 & 0 & 1 & 2 & 3 & 4 & 5 & 6 & 7\\ 9 & 0 & 1 & 2 & 3 & 4 & 5 & 6 & 7 & 8 \end{bmatrix}}$
(c) $\displaystyle{ \begin{bmatrix} 0 & 8 & 7 & 6 & 5 & 4 & 3 & 2 & 1\\ 1 & 0 & 8 & 7 & 6 & 5 & 4 & 3 & 2\\ 2 & 1 & 0 & 8 & 7 & 6 & 5 & 4 & 3\\ 3 & 2 & 1 & 0 & 8 & 7 & 6 & 5 & 4\\ 4 & 3 & 2 & 1 & 0 & 8 & 7 & 6 & 5\\ 5 & 4 & 3 & 2 & 1 & 0 & 8 & 7 & 6\\ 6 & 5 & 4 & 3 & 2 & 1 & 0 & 8 & 7\\ 7 & 6 & 5 & 4 & 3 & 2 & 1 & 0 & 8\\ 8 & 7 & 6 & 5 & 4 & 3 & 2 & 1 & 0 \end{bmatrix}}$
Hint: Use the outer() function and the %% operator.
Use R to calculate the following sums:
(a) $\displaystyle{\sum_{i=1}^{20} \sum_{j=1}^5 \frac{i^4}{(3+ij)}}$ (b) $\displaystyle{\sum_{i=1}^{10} \sum_{j=1}^i \frac{i^4}{(3+ij)}}$
(a) 89912.02; (b) 6944.743
Suppose one wishes to simulate how frequently a new dam will overflow, which depends on the number of rainy days seen in a row. We might start by making observations over some sequence of consecutive days of whether each day was rainy (R) or sunny (S). What we observed is shown below.
RRRRRRRRSSSSSSSRSSSSSRSSSSRRRRRRRRRRSRRRRSSSSSS
It appears that exactly half of the days observed were rainy. As such, one might try to simulate similar data by essentially "flipping a coin" for each day so that the chance that it rains on any particular day is 50%. This would be easy to do in R with the following:
s = sample(c("R","S"),size=28,replace=TRUE,prob=c(0.5,0.5))
paste0(s,collapse="")
Below is some data simulated in this way:
RRRSSSRRRRSSSRRRSRSRRRRSSSRSSRRRSRSSSSSRRSSRRRS
Notice how the simulated sequence doesn't look quite like the actual observed data. In the original data, there are long sequences of R's and S's, while the observed data has much shorter sequences. Granted, this is just one sequence, so additional observations and simulations are made. Strangely, the same pattern is seen in these as well. The observations always seem to have longer subsequences of R's and S's than the simulated data.
Upon reflection, you might realize that one possible reason for the discrepancy is that the probability that any particular day is sunny or rainy is not independent of whether or not the previous day was sunny or rainy. In particular, it appears that if a day is rainy, the probability the next day is rainy is higher than if it was sunny. Likewise, if a day is sunny, the probability the next day is sunny is higher than if it was rainy.
Based on all your observations, it appears that consecutive days have the same weather 90% of the time. With this, we can build the following model:
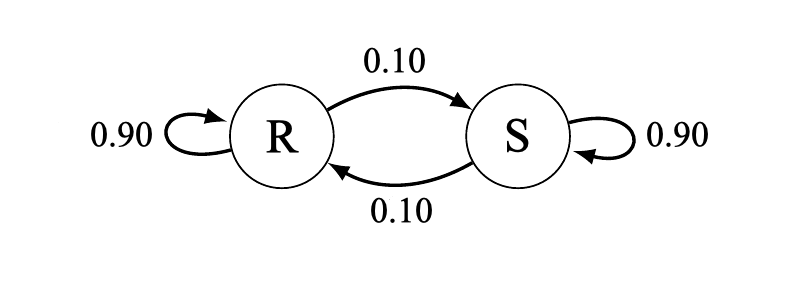

In the model above, there are two "states" (R and S). However, a general Markov chain can have many more. One of the more interesting characteristics of a Markov chain is that the probability that you land in any one state after some number of iterations (i.e., days in the example discussed) can be found through a power of an associated transition matrix.
Let's see how this works...
Suppose it is rainy today (day 1), and you want to know what is the probability that it is rainy or sunny tomorrow (day 2). Of course, the answer is simple -- 90% chance of rain, 10% chance of sun.
Suppose however that you want to know the probability that it is rainy or sunny the day after that (day 3). We can find such a probability using our basic probability rules. For the calculations that follow, suppose $R_i$ is the event "day $i$ was rainy" and $S_i$ is the event "day $i$ was sunny". Then notice:
$$\begin{array}{rcl} P(R_3) &=& P((R_2 \, \& \, R_3) \, \textrm{or} \, (S_2 \, \& \, R_3))\\ &=& P(R_2 \, \& \, R_3) + P(S_2 \, \& \, R_3)\\ &=& P(R_2)P(R_3 | R_2) + P(S_2)P(R_3 | S_2)\\ &=& (0.90)(0.90) + (0.10)(0.10)\\ &=& 0.82 \end{array}$$We could of course use the fact that R and S are complements to find $P(S_3)$, but let's find it in a manner similar to the above:
$$\begin{array}{rcl} P(S_3) &=& P((R_2 \, \& \, S_3) \, \textrm{or} \, (S_2 \, \& \, S_3))\\ &=& P(R_2 \, \& \, S_3) + P(S_2 \, \& \, S_3)\\ &=& P(R_2)P(S_3 | R_2) + P(S_2)P(S_3 | S_2)\\ &=& (0.90)(0.10) + (0.10)(0.90)\\ &=& 0.18 \end{array}$$Similar calculations reveal the probabilities for day 4:
$$\begin{array}{rcll} P(R_4) &=& (0.90)(.82) + (0.10)(.18) \quad & [= 0.756]\\ P(S_4) &=& (0.10)(0.82) + (0.90)(0.18) \quad & [= 0.244] \end{array}$$More generally, we have the following relationship:
$$\begin{array}{rcl} P(R_{i+1}) &=& 0.90 \cdot P(R_i) + 0.10 \cdot P(S_i)\\ P(S_{i+1}) &=& 0.10 \cdot P(R_i) + 0.90 \cdot P(S_i)\\ \end{array}$$Which we could express using matrices with
$$\begin{bmatrix} P(R_{i+1})\\ P(S_{i+1}) \end{bmatrix} = \begin{bmatrix} 0.90 & 0.10\\ 0.10 & 0.90\\ \end{bmatrix} \cdot \begin{bmatrix} P(R_{i})\\ P(S_{i}) \end{bmatrix} $$The middle matrix above (i.e., the one with the 0.90's and 0.10's in it) is called the transition matrix for this Markov chain. It can be applied over and over again to find the probabilities associated with both states after any number of days.
With all of this in mind, write a function p.of.rain() that if it rains on day 1, returns the probability that it also rains on both days 7 and 8.
Remember the events of raining on day 7 and raining on day 8 are not independent!